Training set, Test set e standardizzazione
I modelli supervisionati (classificazione o modelli machine learning) vengono effettuati sulla base di un insieme di addestramento.
Per valutare in modo non distorto le performance predittive dei modelli, il dataset è suddiviso in due parti: training set (80% delle osservazioni) e testing set (20% delle osservazioni). Si sceglie una metodologia di estrazione, solitamente il campionamento casuale.
Poiché le variabili da utilizzare debbono essere espresse nella stessa unità di misura si procede a standardizzare le variabili assunte in input. Si calcolano media μ e varianza σ2 delle distribuzioni di partenza, da esse si ottengono i punti zeta (standardizzati) di ciascuna variabile in base alla seguente espressione:
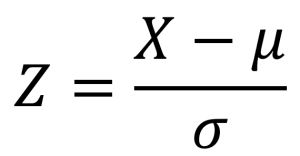
Il dataset di training verrà utilizzato per la stima del modello.
Il dataset di testing sarà tenuto separato dal processo di stima del modello per poter valutare in seguito la performance predittiva.