Quale strada scegliere sulla base dei dati e degli obbiettivi ?
Consulenze statistiche | Analisi ed interpretazione di dati
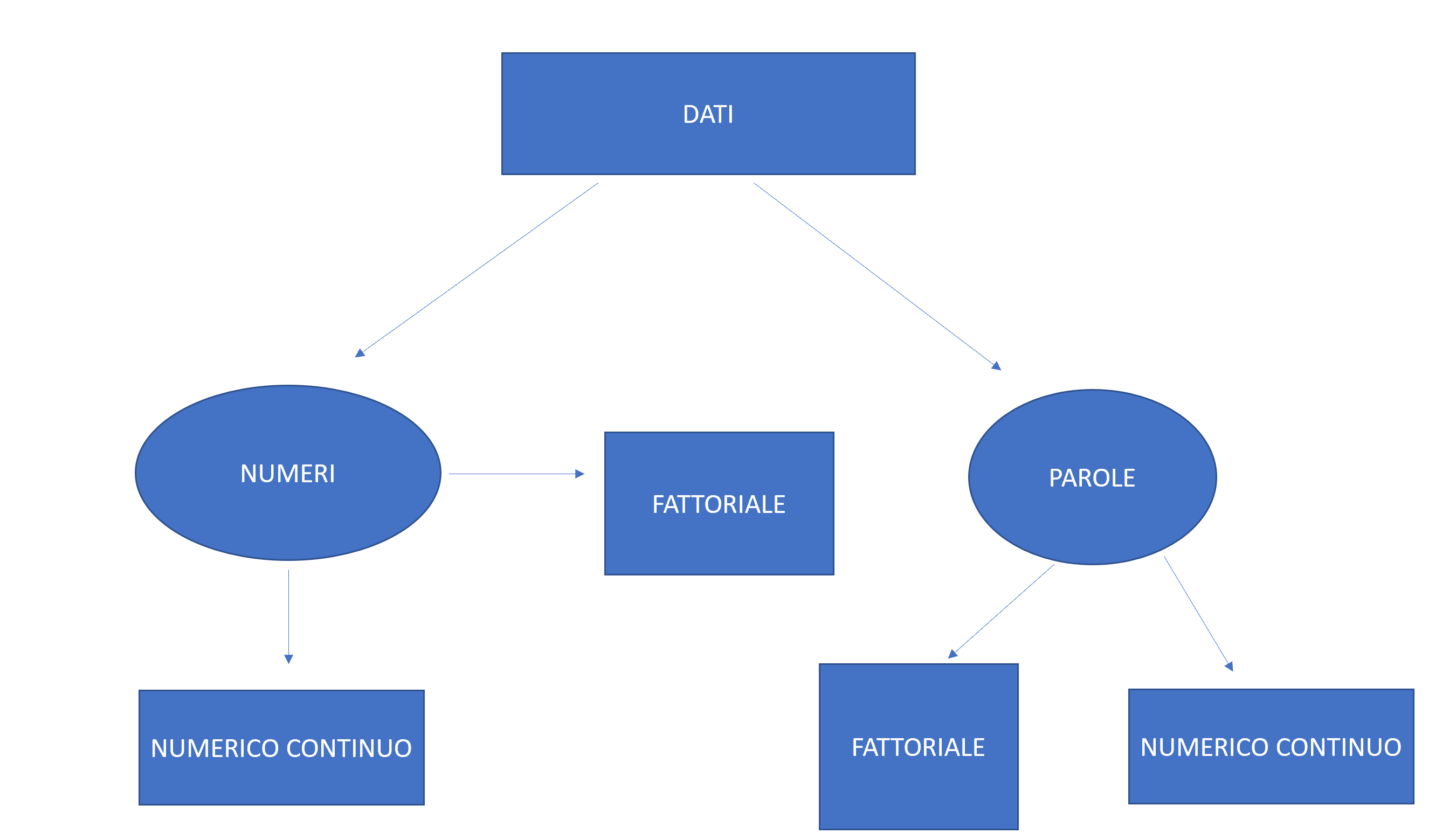
Introduzione alla statistica. Come iniziare un analisi: informazioni utili prima di partire con un analisi statistica. Come impostare un buon lavoro. Come individuare errori nel dataset.
I modelli supervisionati (classificazione o modelli machine learning) vengono effettuati sulla base di un insieme di addestramento.
Per valutare in modo non distorto le performance predittive dei modelli, il dataset è suddiviso in due parti: training set (80% delle osservazioni) e testing set (20% delle osservazioni). Si sceglie una metodologia di estrazione, solitamente il campionamento casuale.
Poiché le variabili da utilizzare debbono essere espresse nella stessa unità di misura si procede a standardizzare le variabili assunte in input. Si calcolano media μ e varianza σ2 delle distribuzioni di partenza, da esse si ottengono i punti zeta (standardizzati) di ciascuna variabile in base alla seguente espressione:
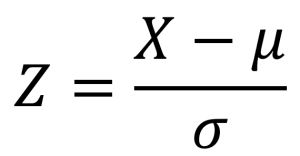
Se hai raccolto i tuoi dati ricordati che la qualità dei dati è importantissima per la tua analisi.
Prima di eseguire qualsiasi test o modello è necessario:
Se tutti questi 3 passi sono stati eseguiti correttamente, avrai dei dati che, statisticamente parlando, sono buoni per la analisi e avrai un idea, grazie alle statistiche descrittive, di come sia composto il tuo campione. Da ciò potrai formulare ipotesi da testare con i modelli o test.
Leggi tutto “3 passi fondamentali per la preparazione dei dati”
Gli outlier sono valori numericamente distanti dal resto dei dati raccolti, ovvero sono valori estremi. Le analisi che derivano da campioni contenenti outlier presenteranno risultati anomali. Il consulente statistico si occupa di comprendere la natura degli outlier, in base alla quale applicherà modelli o test più robusti per l’analisi che consentiranno di ottenere risultati attendibili.
Attenzione gli outlier non sono per forza errori!
Leggi tutto “Outlier: valori anomali, come individuarli e trattarli?”
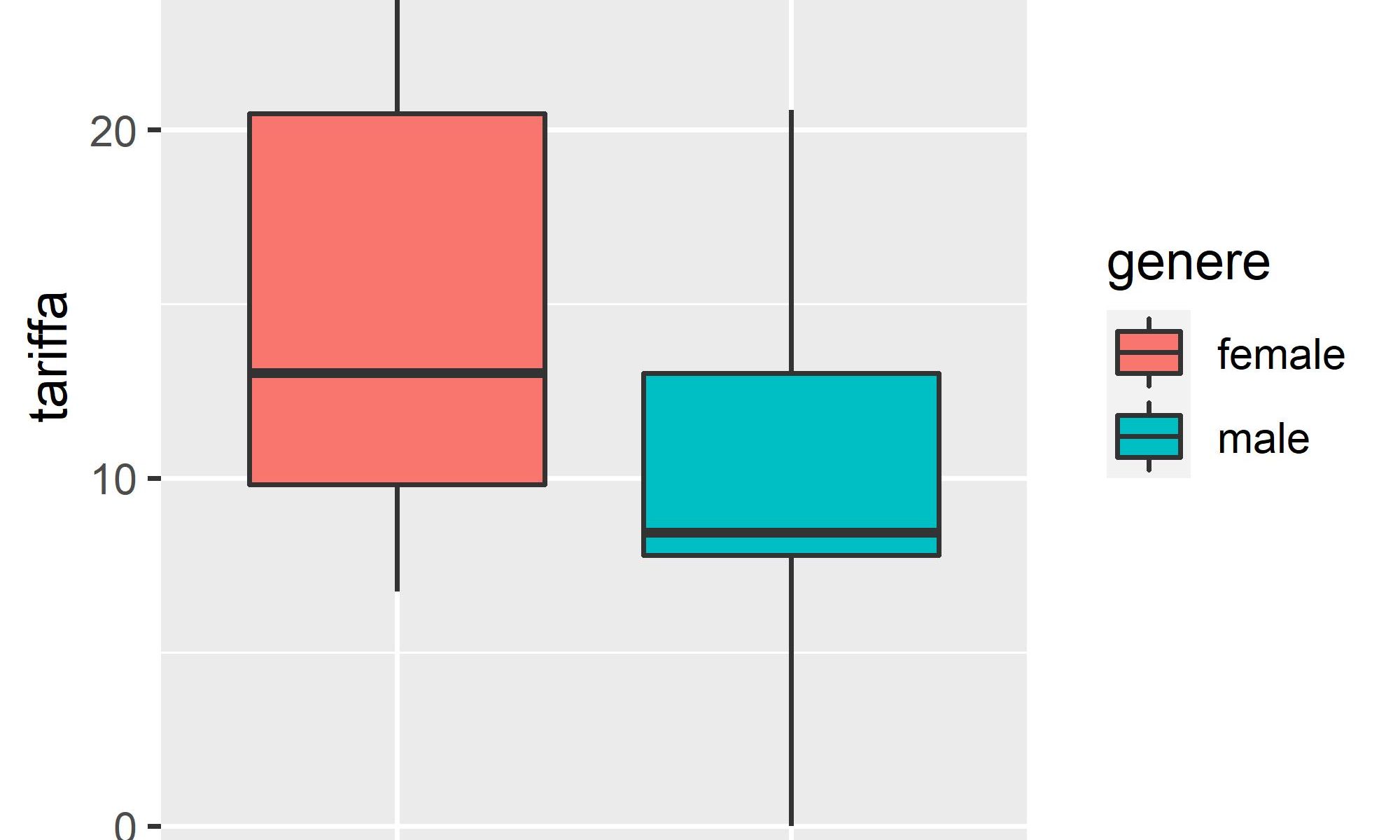
La statistica descrittiva è composta da vari indici usati per descrivere e sintetizzare le caratteristiche di base dei dati raccolti. Insieme alla semplice analisi grafica, la statistica descrittiva costituisce la base di partenza di qualsiasi analisi.
Leggi tutto “Cos’è la statistica descrittiva?”